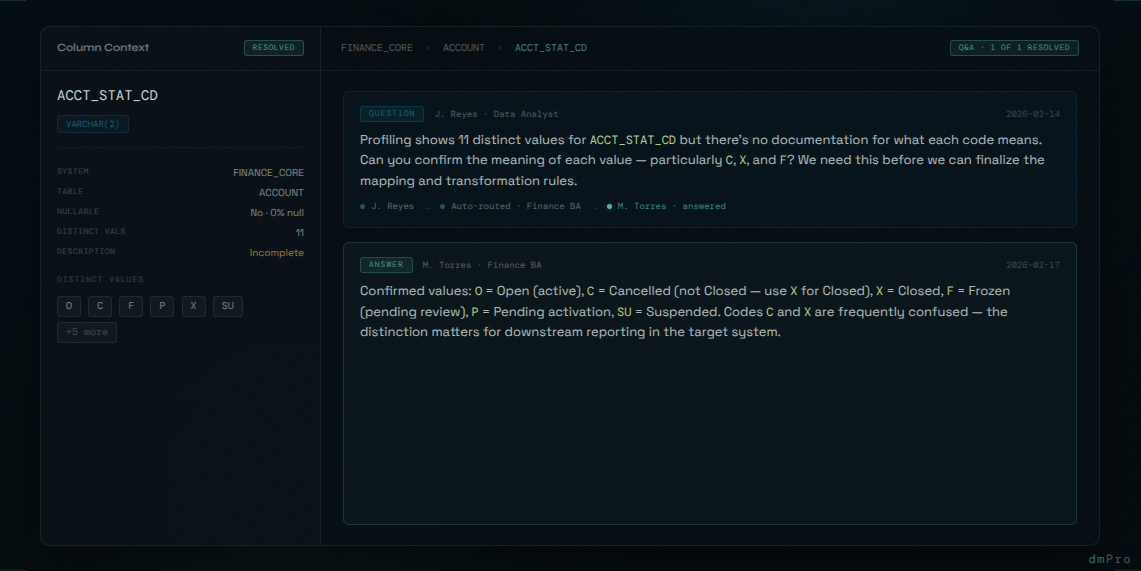
It's week two of a data migration project. An analyst is working through the source columns for the legacy financial system and hits a field called ACCT_STAT_CD.
The profiling results show eleven distinct values: single and double-character codes. The column description says "Account status code." That's it. The person who built the original system left the organization four years ago. There's no data dictionary. There's no functional spec that explains what each code means.
The analyst does what every analyst does: she sends an email to the client's DBA. Subject line: "Question about ACCT_STAT_CD values." She includes the table name, the column name, a screenshot of the distinct values from profiling, and a request for an explanation of what each code represents.
The DBA isn't sure either. He forwards it to a business analyst on the client side. She's on vacation. The email sits for a week. When she returns, she has 200 emails and a backlog of meetings. The question about ACCT_STAT_CD is answered on day seventeen — more than two weeks after it was asked.
By day seventeen, the analyst is behind schedule. She made her best guess based on the values and moved on. "C" probably means Closed. "O" is obviously Open. "F" might be Frozen. She wrote those interpretations into the description field, created the mapping, and moved on to the next table.
In UAT, a business user looks at migrated records and flags them. "C" doesn't mean Closed — it means Cancelled. Closed is "X." They're different statuses with different downstream implications in the target system. The mapping is wrong. The fix requires correcting the mapping, updating the job specification, reloading affected records, and retesting.
This story — or a version of it — plays out on every large data migration project. The knowledge exists. The problem is getting it from the person who has it to the document that needs it, reliably, before the work that depends on it moves forward.
Why Migration Questions Are Structurally Hard
Migration questions aren't a communication failure — they're a structural problem. The nature of the work creates conditions where knowledge loss is almost inevitable.
First, the questions are highly specific. They're not general questions about a system — they're questions about the meaning of particular columns in particular tables, often with business context that only a handful of people understand. Finding the right person to ask requires knowing who that person is, which is itself often unclear.
Second, the questions arise in volume. On a large migration project, hundreds of such questions come up during the cataloguing and mapping phases. Each one is individually small — a few minutes to ask, a few minutes to answer. But collectively they represent a significant coordination burden, and managing them through informal channels (email, Slack, ad hoc meetings) means the overhead of tracking and following up falls on the people who can least afford it.
Third, the answers have value beyond the individual question. When a DBA explains that "C" means Cancelled rather than Closed, that answer is useful not just for the analyst who asked — it's useful for the QA analyst who writes the test case, the ETL developer who defines the transformation logic, the compliance reviewer who traces the data lineage, and the next project team that migrates from the same source system. But when the answer lives in an email thread, none of those other people can find it.
Fourth, the unanswered questions create pressure to guess. Deadlines don't flex to accommodate slow response times. When an analyst is blocked waiting for an answer, the rational response under time pressure is to make the best guess available and move on. Some guesses are right. Some are wrong. The wrong ones compound.
How dmPro's Q&A Workflow Works
dmPro treats questions as a first-class feature of the data migration workflow — not as an external communication problem to be solved by other tools.
When an analyst encounters something they don't understand, they create a question directly in dmPro. The question is attached to the specific item it concerns: a legacy column, a target field, a data quality rule, a mapping decision. It can't float free of context the way an email subject line does.
The question is routed to the appropriate person based on the project's configuration — typically by business area, data domain, or role. The assigned person receives a notification. They open the question, see the context (the column name, the profiling results, the business area, any existing description), and provide an answer. The analyst who asked gets notified and can immediately return to the work that was waiting on the answer.
The answer is stored permanently in the project record. It's searchable. It's visible to everyone on the project team. It's tied to the specific table it describes. The next time anyone on the team — or any future team — encounters that column, the answer is already there.
Knowledge Management as a Migration Risk Factor
It's common to think about knowledge management as a nice-to-have: good for onboarding, helpful for documentation, but not really a risk factor. On data migration projects, that framing is wrong.
The knowledge embedded in legacy systems is fragile. It exists in the heads of people who may be leaving the organization during or after the migration, in documents that may be incomplete or outdated, and in institutional patterns that were never explicitly documented. The migration project is often the last moment when that knowledge is actively needed and the people who have it are still available. After go-live, the context disappears.
When that knowledge is captured in a structured, searchable form — attached to the specific data it describes, in the project system that the whole team uses — it becomes a project asset rather than a liability. The cost of capturing it is low: the analyst creates the question, the DBA answers it. The benefit is high: the answer informs the mapping, the job spec, the test case, and the audit trail.
The alternative — email threads that nobody can find, Slack conversations that scroll past, undocumented assumptions that become incorrect mappings — is a risk factor that shows up consistently in project post-mortems. Not in the analysis section. In the "what we'd do differently" section.
The System Integrator Perspective
For system integrators, the knowledge management dimension is particularly important because the knowledge gap is structural. SI analysts understand data migration methodology. Client staff understand the legacy system and the business processes it supports. Neither group has the other's knowledge at the start of the project.
The Q&A workflow in dmPro is designed for exactly this dynamic. Client staff are first-class participants in the project — they receive questions, provide answers, and can view the context that motivated each question. They don't need to understand data migration methodology to participate effectively. They just need to understand their own system.
And critically: the answers they provide become part of the permanent project record, not part of an SI-owned email archive that leaves the organization when the project closes. The client ends up with documentation of their own legacy system that they didn't have before the migration started — derived from the work of the migration itself.
This is a concrete deliverable that often goes unrecognized. The data dictionary that emerges from a well-run migration project in dmPro — descriptions generated and reviewed, questions asked and answered, decisions documented — is more accurate and more complete than anything the client had on day one. That has value beyond the migration itself.
The Audit Trail Dimension
In regulated industries — government, healthcare, finance, insurance — the ability to demonstrate that decisions were made deliberately, by qualified people, with documented rationale, is not optional. Regulatory requirements for data traceability extend to the migration process itself: how the data was interpreted, how mappings were determined, what questions arose and how they were resolved.
A Q&A record in dmPro answers a specific class of audit question: "How did the team determine the meaning of this field?" The answer is: here is the question that was asked, here is who was asked, here is the answer they provided, here is when it was answered, and here is how that answer was reflected in the project documentation.
That's a fundamentally different audit position than "we think the analyst asked the right people and documented what they found." One is traceable. The other is reconstructed from memory.
What Stops Working Without This
The absence of a structured Q&A workflow doesn't mean questions don't get asked. It means they get asked in ways that don't produce durable answers. Email threads. Hallway conversations. Meeting notes that only one person took. Slack channels that are archived when the project ends.
The consequences show up in two places: project quality and institutional knowledge. Project quality suffers when questions go unanswered and analysts guess. Institutional knowledge disappears when the answers that do exist are locked in communication tools that nobody indexes or searches.
Neither consequence is visible in a status report. The guesses look like completed work. The lost knowledge looks like absence of documentation. Both become visible later — in UAT, in post-launch issues, in the next migration project that has to rediscover what this one already figured out.
Structured Q&A doesn't eliminate uncertainty. It makes uncertainty visible, routes it to the right people, and captures the resolution. That's the specific problem it solves — and it's a problem that every data migration project has, whether it's managed or not.