Let me share a pattern I've seen play out on project after project for 25 years. A large system modernization kicks off. The implementation team selects their tools, sets up environments, starts building. Everything looks good. Then someone asks about the data migration, and the answer is almost always the same: "We'll figure it out. Set up some spreadsheets." What follows is a cascade that turns a manageable workstream into the project's biggest liability.
How the Cascade Starts
It begins innocently enough. The data migration lead creates a few spreadsheets to catalog legacy data sources and define source-to-target mappings. The approach feels reasonable — spreadsheets are flexible, everyone knows how to use them, and the project doesn't want to spend time or budget on specialized tooling for a "temporary" workstream.
But data migration is never simple. As the team digs into the legacy systems, complexity emerges. More tables than expected. Undocumented fields. Business rules embedded in stored procedures. Data quality issues that weren't in any requirements document.
Each new discovery means another spreadsheet, another tab, another column. Six months in, the migration team is managing 40 or more spreadsheets. The mapping document alone might have dozens of tabs. The data quality tracker is its own ecosystem of files.
The Compounding Effect
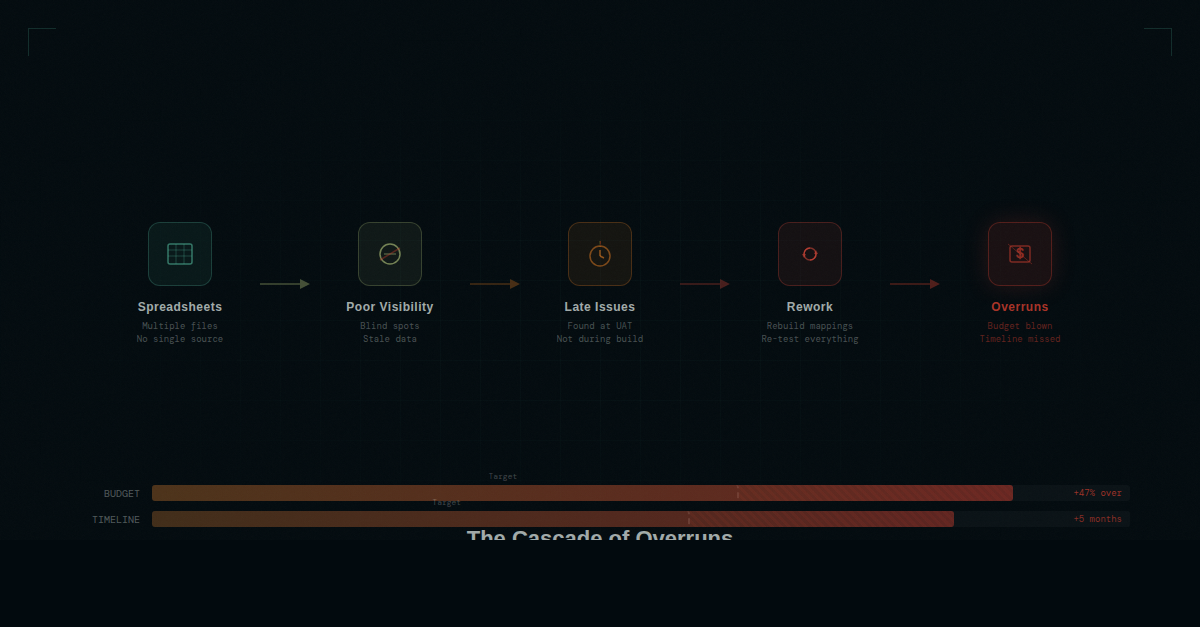
Here's where the real cost emerges. It's not just the inconvenience of managing too many spreadsheets. It's a compounding cascade where each problem creates the next:
- Poor tooling leads to poor visibility. When migration status lives in dozens of spreadsheets maintained by different people, no one has a clear picture of where the project actually stands. The PM spends hours before each status meeting manually aggregating data from multiple files, and even then the picture is incomplete.
- Poor visibility leads to late-discovered issues. Without a clear, real-time view of migration progress and data quality, problems hide. A mapping gap that should have been caught in analysis doesn't surface until integration testing. A data quality issue that could have been flagged during profiling isn't found until UAT.
- Late-discovered issues lead to rework. Finding problems late means fixing them late — when the cost of change is highest. A mapping correction during analysis is a five-minute spreadsheet update. The same correction during testing means modifying ETL code, re-running jobs, re-testing, and updating documentation. A single late-discovered issue can consume a week of team effort.
- Rework leads to overruns. Multiply that rework across dozens or hundreds of late-discovered issues, and you have a project that's significantly over budget and behind schedule. The migration becomes the bottleneck. The go-live date slips. Other workstreams that are ready to go are held up waiting for the migration to catch up.
This isn't a theoretical cascade. I've watched it happen on project after project. The specific details change, but the pattern is remarkably consistent.
The Human Cost
Beyond the budget and schedule impact, there's a human cost that rarely gets discussed. Migration teams working under these conditions burn out. They're managing complexity with inadequate tools, constantly firefighting issues that better tooling would have prevented, and bearing the pressure of being the workstream that's holding up the entire project.
The migration lead spends more time managing spreadsheets than managing the migration. Team members waste hours searching for information, reconciling conflicting versions, and manually updating status trackers. The work that actually matters — analyzing data, designing transformations, solving complex mapping problems — gets squeezed by administrative overhead.
What "Good" Looks Like
The opposite of the spreadsheet cascade is what I call structured migration management. It looks like this:
- Single source of truth: One system that holds the complete data landscape — legacy sources, target structures, mappings, transformation rules, data quality results, and test outcomes. No version conflicts. No hunting for the latest file.
- Real-time visibility: Dashboards that show migration status at every level — from project-wide health down to individual column mapping status. No manual aggregation. No stale reports. The PM can answer "what's the status?" in seconds, not hours.
- Early issue detection: When data quality results, mapping progress, and test outcomes are all connected in one system, patterns emerge early. You can see that a particular legacy system is behind on profiling before it becomes a critical path issue. You can spot data quality trends that predict downstream problems.
- Structured workflows: Instead of ad-hoc spreadsheet processes, a defined workflow that moves each data element through cataloging, profiling, mapping, transformation development, testing, and sign-off. Every step is tracked. Nothing falls through the cracks.
- Audit trail: Every change to a mapping, every data quality decision, every test result — captured with who, when, and why. When something goes wrong, you can trace the history. When an auditor asks a question, you have the answer.
The biggest risks on a migration project are the ones nobody sees coming. When your tooling doesn't give you visibility, problems hide until they're 10x more expensive to fix.
Breaking the Pattern
I've spent 25 years watching this pattern repeat because there was no alternative. Migration teams used spreadsheets because that was all that was available. The pain was accepted as a cost of doing business.
But it doesn't have to be this way. Data migration deserves the same level of tooling as every other critical workstream. When you give a migration team proper tools — tools that provide structure, visibility, and control — the cascade doesn't start. Issues surface early. Status is always current. The migration stops being the project's biggest risk and becomes a managed, predictable workstream.
That's the standard every migration project should be held to. And now, the tooling exists to make it possible.